Using Google Search Data for Planning and Outreach
Peter Velikonja, Head of Research, Koios LLC
www.koios.co | peter (at) koios.co
delivered ALA Midwinter Conference January 2019, CIL Conference March 2019
Abstract
Libraries generally have a good idea of what their patrons are interested in, but Google, to whom patrons routinely address their questions, has the data.
Using Google's API, we tried out a few hundred themed key-phrases in 3000 public library service areas. The results confirmed some of our assumptions, and
also included surprises. A survey like ours can inform library marketing efforts, and help administrators with resource management and planning.
Motivation
At our company, we work to raise the online presence of libraries, which we do today with Google advertising.
We say, somewhat poetically:
"When a person begins their journey, seeking
information, where do they go first? They go to Google. Let's meet them there."
It's a good story, and it rings true.
We try to anticipate what a person might search for:
We think of the resources available at a library.
We set up a collection of likely keywords with Google; then...
Hope to make a match.
Example
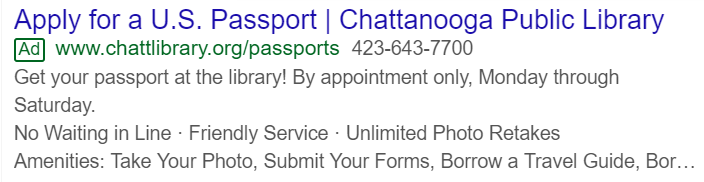
Let's say you live in
Chattanooga TN and you type 'passport' into Google...
You might see an ad we set up there that tells you your local library runs a passport service. And you say "I had no idea..."
That's a situation where a library has a resource people are interested in, but nobody knows it.
Another is where a library wishes to start up a program, but can't fully anticipate community interest.
Our business is about making those connections.
Connections Part II
To make more connections, I want to think about intersections between:
a set of library resources, and
what people type into Google
I can learn about library resources, they are publicly available. But what do people type into Google?
I don't know.
What do people type into anything? Let's look at two feeds.
Toronto Public Library - Catalog Feed
I really like this catalog feed from Toronto Public Library, I
find it mildly exciting to see these searches being made in real time. But I confess I get a little bit stuck
when I start thinking about what I can do with it. Do these searches represent community interests? I think
they do, although I remind myself that people are more likely to pre-focus their searches to fit their understanding
of library resources. Libraries are full of surprises these days, I doubt these searches can keep up.
Real-Time Twitter Feed
I am not so crazy about this Twitter feed (taken real-time from Seattle) because, at the root of it, these entries
don't have search motivation. Yes, they represent interest, and with my own personal AI (or 'WI') I can see themes
and keywords pop out that are relevant to libraries. But having interest is not the same as expressing
interest; so this stream has considerably less value for me.
Twitter feed [click]
Library Themes
Realistically, Twitter posts are too general for me and I can see the catalog feed is already too focused for
me. But I can't really use either without categorization.
Words falling from the sky are great, they represent interest coming from the public. But if I want to
know how this rain relates to my programs, I gotta put out some buckets.
Themes I chose for this research project.
Using Google Ads API to Find Keywords
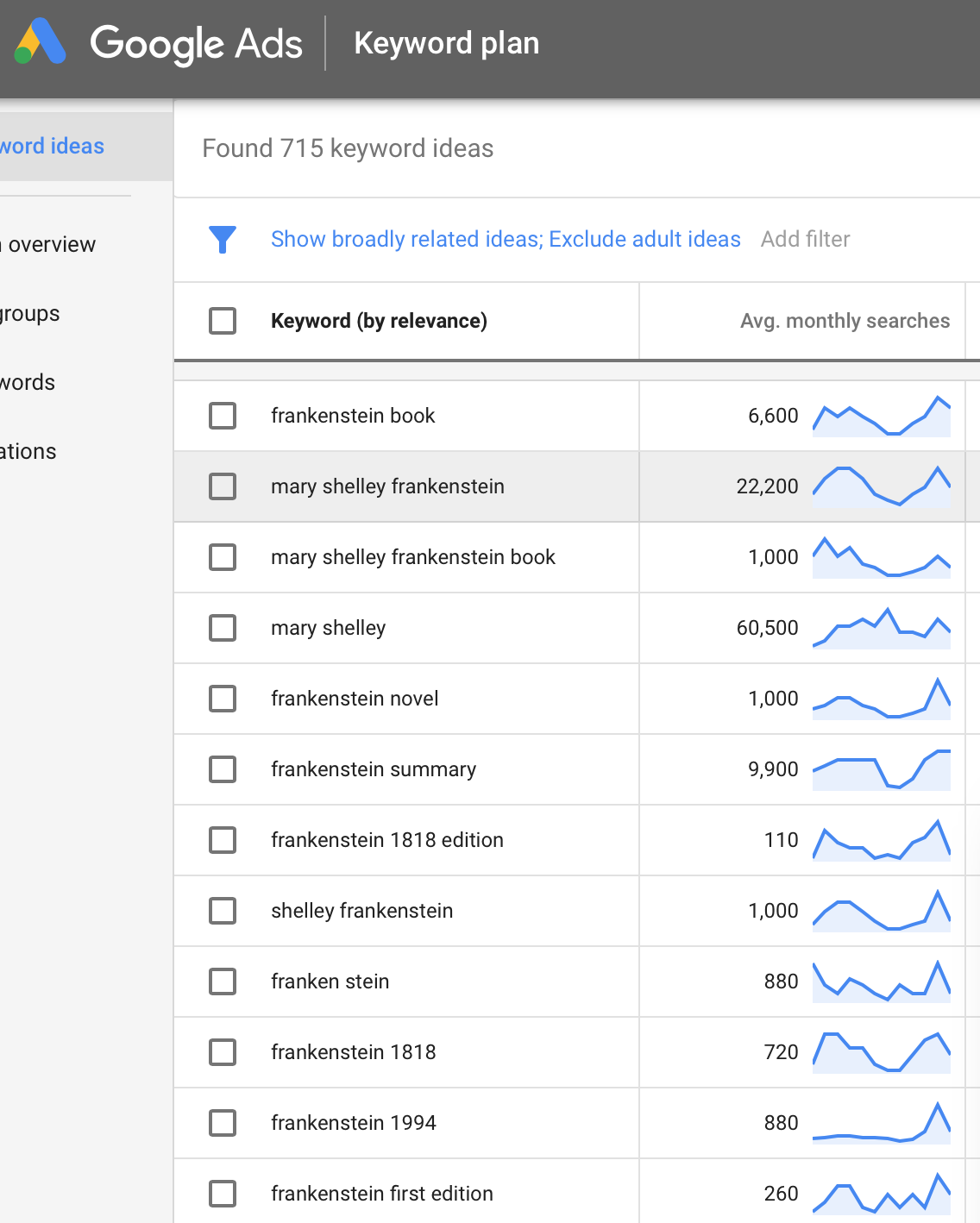
When you advertise with Google, they provide you with a number of handy research tools; one of
them is a keyword-ideas generator: you send Google a word or phrase and you get back a crazy list
of alternatives that they think are related. If I try 'Frankenstein'
I get back 'Mary Shelley' and some other stuff that is usually related (but not always).
Frankenstein 'ideas' volume+keyword [click]
Passport 'ideas' volume+keyword [click]
A Google advertiser uses these ideas to form a thematically grouped set of keywords called a campaign.
Targeted Search Volume
You can see in the image that, with each permutation on 'frankenstein', Google gave me a value for average monthly
searches (for the US). That's nice, especially because I can target a location for a keyword and get back
the number of searches for an individual keyword in a specied location -- from country, state, county, city, down to zip code.
Now that's handy, because if I send in a group of related keywords, and specify a unique location, I can perhaps
get a snapshot of user interest for a particular theme, in a defined place. Let's say I try Frankenstein,
Dracula, Klaus Kinski, and Boris Karloff in different locations, I get:
I infer from this that people in Portland lean toward monster movies.
Community Insights
There are about 9000 public libraries in the US, I took the 3000 largest, and got location-specific search volumes for
the themes I articulated above (passports, how-to ...).
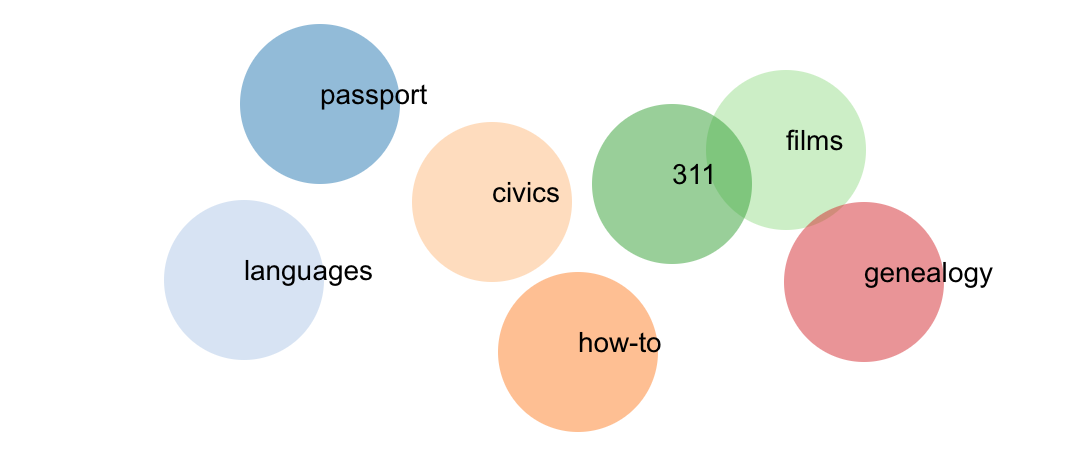
In this visualization, a campaign-theme is presented as a word-cloud. The size of each word
tells you how often it appears in the campaign (passport, get a passport, passport application) and its
intensity tells you the search volume associated with it -- so the word can be small, but if it is very
blue it means people type it in a lot. I called it a campaign-tuner because it can be used to weed out
low-interest keywords and to identify the higher-performing ones.
I can dial up a library (click library name at top and enter a new one) and read its tea leaves. The word cloud gives
an initial impression of the campaign, the real interest lies in the high-volume keywords within those groups.
USA Profile
passport: [service] tells libraries considering a passport program that people are interested
languages: [culture] sign language consistently at the top of this list
how-to: [skills] originally a Lynda-oriented list, topped consistently by how to draw, then python
genealogy: [identity] national interest is high because of cheap DNA testing, but obituaries still dominate
civics: [civics] voting, taxes, volunteering...taking the temperature of civic engagement
films: [culture] horror movies win
my311: [service] hospital near me, and, in certian hot spots, traffic
Comparing Libraries to US Standard
Now I want to look at relative strengths betweencommunities using the
whole of US for reference.
Distance from US Profile
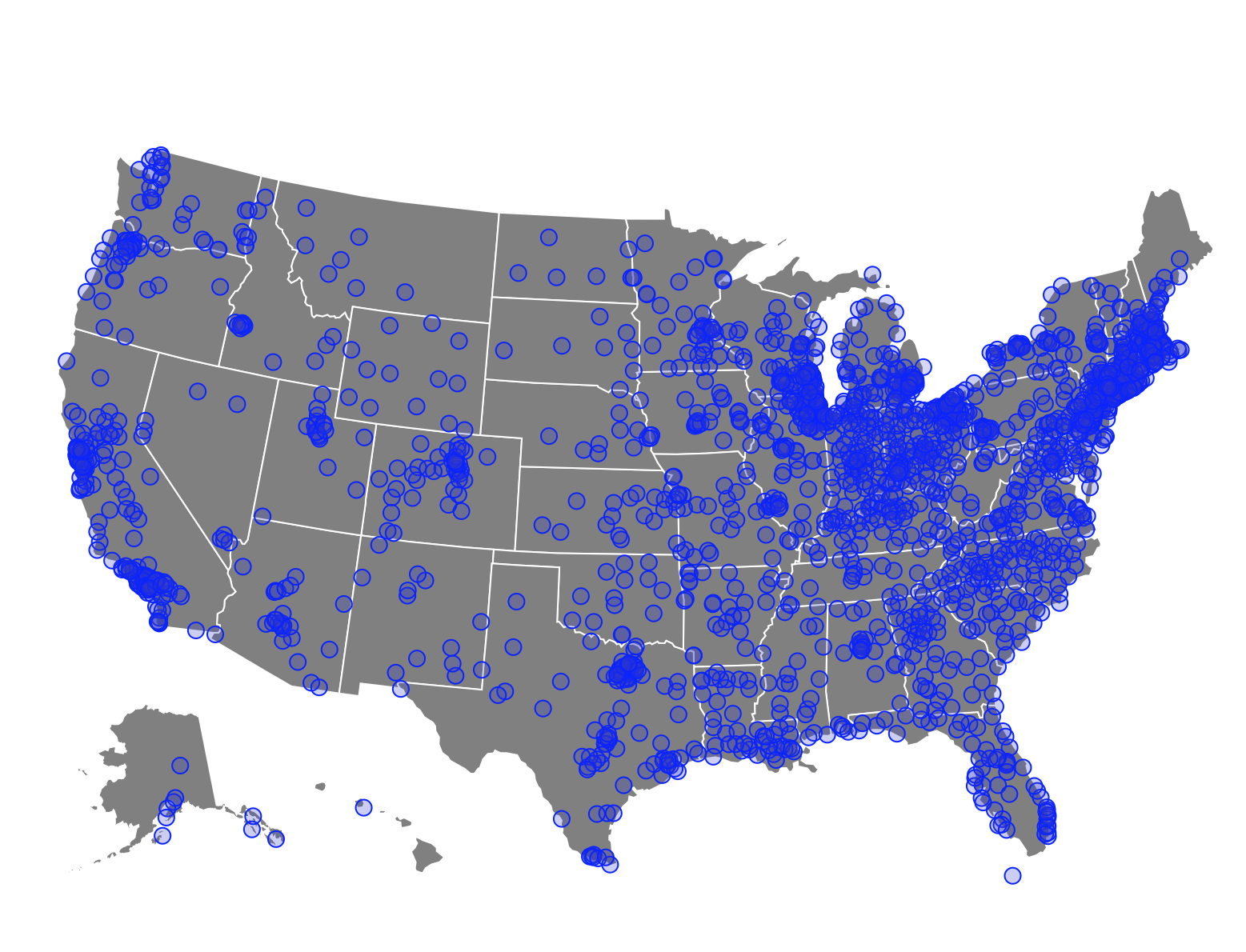
When this demo first fires up, it shows relative search volumes for the US. The plot at the top (looks like
an audio signal) shows the 3000 polled libraries. The height of each is its population (not service pop),
or, actually, Google's idea of reach. With the slider on the bottom you
can zip past lots of libraries in a hurry. The point of this plot is to give a high-level view, and you can see how
individual libraries compare to the US profile.
What we see in this demo is that, yes, there are variations, but mostly there is remarkable continuity.
Hot Keywords
Another lesson learned here is about grouping. You would think that somehow community interests would express
themselves through one of these themes, and you would see a group of words amplified, but it doesn't really
seem to work that way. Instead we see individual keywords vault to the top, pulling the group up with them.
The wordcloud visualization is good for these accidental discoveries.
If we look at how the same theme plays across different libraries, it seems that the
same keywords are always there at the top. If a different keyword sneaks to the top once in a while it is a pleasant
surprise, and, since it is unusual, it is an indicator.
When we see a pattern that steps out of the norm, we can look into it and see where it leads.
Measuring Public Interest
A strategic planning process generally includes an effort to learn what the public is interested in.
A survey is a traditional way to accomplish that, but it is a deeply flawed method.
A survey may not reach enough of the public to be statistically valid
It tends toward self-reinforcement
Examples
In Arlington VA (pop. 230K) a 2018 survey collected 14,506 responses (in 22 days), our survey shows 19.5K monthly searches matching the 7 themes I chose.
In Rye NH (pop. 5500) the library mailed out 3000 questionnaires and got back 244 (~8%). In our survey the results are too noisy to determine anything, but 2500 searches per month...that has potential
(see also: Farmingdale NY skewed by age).
To complement a survey, libraries look for something wider and flatter.
They observe computer users, for example, convene a focus group, or examine census data.
Website Data
Let's go back to Toronto. I harvested the feed we saw above for the month of December (2018) and collected
almost 800,000 searches, so I let it go a bit longer until I had 1M.
Their search bar is at the top of their home page and is a catalog
search with a few general items thrown in (like 'get a library card'). If I pass those searches through the same
themes I have been using, I get about 2600 matches, and I
can compare that profile to the Google search profile.
If we can get past the scale difference, the library search profile looks different than the Google-derived profile, which
should interest strategic planners thinking about reaching new patrons.
'Criterion Collection' is roughly the same. And yes, the 'passport'
theme is empty: a million searches and nobody typed in 'passport'. Actually, I found that so
incredible that I went back and checked, and I found two searches:
passport and ballot
library passport
So you have, from the general public, some opportunities:
6000 passport searches (monthly)
1000 searches for the Toronto Film Festival
2900 freelancing searches
Summary
The goal of this analysis is to discover intersections between library resources and public interest areas.
In a Nutshell
Google exposes some of its search data results, which you can examine in Google Ads.
A library that wants better to understand public interest can supplement its surveys with wider, flatter data.
Ground-truthing with search data can help distinguish fashion from trends.
You can discover search interest, weigh against average, and compare with peers.
Thanks, Buddy, Now How Can I Do This Myself?
First you can look at the profile for your library I created and see if anything there catches your interest.
Then you can create a Google Ads account and try the Keyword Planner even if you don't intend to advertise.
The ideas you get from the planner can focus your Google Trends inquiries.
You can crack open your web server logs and count searches.
If you want to take on a bigger project, and you have programming resources, you can sign up to use Google Ads API.